Posts

Getting started with h2o4gpu
(best viewed on original website)
Over the last year, my focus has been diverted from exploring analytics, new packages and blogging, to completing my dissertation. With the dissertation now complete and only final edits remaining, I had some spare time to spend on projects that I have been curating throughout the year. One such project that has been in the back of my mind for the last couple of months concern itself with with faster, scalable machine learning.

Scaling H2O analytics with AWS and p(f)urrr (Part 3)
H2O + AWS + purrr (Part III) This is the final installment of a three part series that looks at how we can leverage AWS, H2O and purrr in R to build analytical pipelines. In the previous posts I looked at starting up the environment through the EC2 dashboard on AWS’ website. The other aspect we looked at, in Part II, was how we can use purrr to train models using H2O’s awesome api.

Scaling H2O analytics with AWS and p(f)urrr (Part 2)
H2O + AWS + purrr (Part II) This is the second installment in a three part series on integrating H2O, AWS and p(f)urrr. In Part II, I will showcase how we can combine purrr and h2o to train and stack ML models. In the first post we looked at starting up an AMI on AWS which acts as the infrastructure upon which we will model.
Part one of the post can be found here

Analysis of South African Funds
Packages used in this post Disclaimer: I am no financial advisor, have never been and you should not take any of this analysis as investment advice. These thoughts are my own, please dont mail me about your money strategies/problems. I enjoy numbers, scraping and data analysis and that is wat this post is about. Also, do you really want to trust someone who wrote this post at 2am… no you dont

Scaling H2O analytics with AWS and p(f)urrr (Part 1)
H2O + AWS + purrr (Part I) In these small tutorials to follow over the next 3 weeks, I go through the steps of using an AWS1 AMI Rstudio instance to run a toy machine learning example on a large AWS instance. I have to admit that you have to know a little bit about AWS to follow the next couple of steps, but be assured it doesn’t take too much googling to find your way if you get confused at any stage by some of the jargon.
Interacting with AWS from R
Getting set up If there is one realisation in life, it is the fact that you will never have enough CPU or RAM available for your analytics. Luckily for us, cloud computing is becoming cheaper and cheaper each year. One of the more established providers of cloud services is AWS. If you don’t know yet, they provide a free, yes free, option. Their t2.micro instance is a 1 CPU, 500MB machine, which doesn’t sound like much, but I am running a Rstudio and Docker instance on one of these for a small project.

Workshop in Cape Town: Web Scraping with R
Join Andrew Collier and Hanjo Odendaal for a workshop on using R for Web Scraping.
Who should attend? This workshop is aimed at beginner and intermediate R users who want to learn more about using R for data acquisition and management, with a specific focus on web scraping.
What will you learn? You will learn:
data manipulation with dplyr, tidyr and purrr; tools for accessing the DOM; scraping static sites with rvest; scraping dynamic sites with RSelenium; and setting up an automated scraper in the cloud.
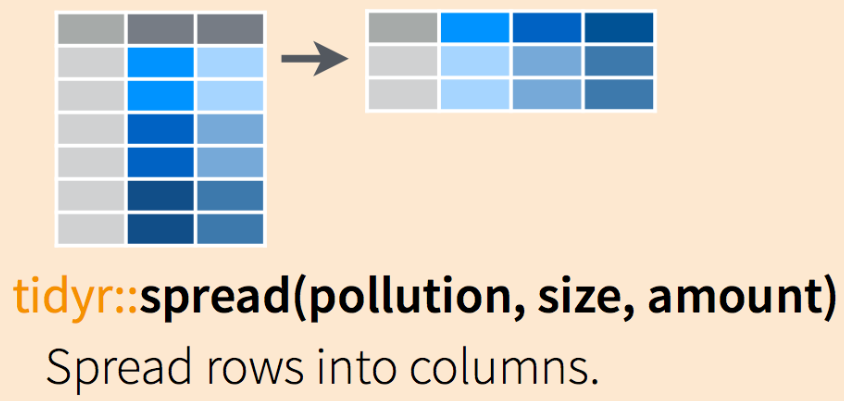
Workaround for tidyr::spread with duplicate row identifiers
The problem The tidyverse api is one the easiest APIs in R to follow - thanks the concept of grammer based code. But every now and again you come across an error that boggles your mind, my personal one is the error spread delivers when I have no indexing for my data: Error: Duplicate identifiers for rows (2, 3), (1, 4, 5).... I am sure we have all seen this some or other time.

Rstudio + Selenium + AWS: Deep in Docker Hell
As with most data scientist, there comes a time in your life when you have enough false confidence that you try to build production systems using docker on AWS. This past weekend, I fell in this trap. Having recently attended a R-ladies event in Cape Town that dealt with the topic of Docker for Data Science, I achieved a +5 docker confidence bonus - and you know what they say about having a new hammer… you look for anything that looks like a nail!
Moving columns using basic english prepositions!
Moveme! I recently worked with a dataset that had over 100 columns and had to keep moving the order of the columns such that I could easier conduct my analysis. For example, whenever you try and conduct a multiple-factor analysis (FactoMineR::MFA), the function requires specific grouping of your variables to conduct the analysis. This meant that after feature engineering, I was left with the problem of having to order my columns so that the analysis could be run.