
H2O + AWS + purrr (Part I)
In these small tutorials to follow over the next 3 weeks, I go through the steps of using an AWS1 AMI Rstudio instance to run a toy machine learning example on a large AWS instance. I have to admit that you have to know a little bit about AWS to follow the next couple of steps, but be assured it doesn’t take too much googling to find your way if you get confused at any stage by some of the jargon.
- Part I of this III part series will show you how to get the infrastructure working on AWS.
- Part II will showcase how we can combine
purrrandh2oto train and stack ML models2. - Part III, the final installment in the series, will show you how we can use
furrr,reticulate-boto3andAWSto spin up remote machines from your local work environment, but train remotely. Have you ever dreamt of running ML models on a 150 core 2TB RAM machine? Well, for a couple of dollars, I am going to show you how.
If you havent got an AWS account already, set one up now if you want to follow along with the rest of this series.
Why I moved to H2O from caret
I have always been a big fan of the caret package. It was my introduction into machine learning in R. Its modular framework allowed for a very experimental environment. It allows for the exploriation of effects such as class imbalance on the outcome, with options such as SMOTE, ROSE an Up and Down sampling, while easily allowing for K-folds (and repeated K-folds) cross-validation. It also lets the programmer configure a training grid for mulitple hyperparameter specifications allowing for very fine tuning of the models. Lastly, lets not forget the fact that there are over 200 models to play with.
H2O does most of this, but allows for a much more “programmatic” approach to the problems. After the first couple of interactions with the api, you start to enjoy the bulletproof engineer of the underlying code. It does not offer the wide array of features of caret, but it has the big 5: glm(net), rf, gbm, xgboost, deeplearning, and also stacking of the models. H2O allows for a much easier programming journey to a production ML system. The robust engineering strategy allows us to scale the ML training for a much larger experimental design.
I think caret is very good if you only need to run a single model that we need to tune and experiment with - i.e academia and small scale ML applications. H2O on the other hand is does a lot of the nitty gritty in the background for you which is great for production:
- If removes constant columns
- It doesn’t break if it sees an unknown factor variable
- It has early stopping which is easily implemented
- Exploits multicore and gpu processing in a much more effective manner
- Does crazy amounts of logging for any errors that might creep up3
Lastly, and certainly important if you gonna train a couple of models: its fast!
In my case, I was looking for a profit optimisation model over multiple markets (~80) for which I wanted to introduce a rolling window design, check performance of rf, gbm, xgboost and in the end put model in production with short delay. This is a lot of modeling and H2O made all of this ‘easy’-ish.
Introducing AWS
If you haven’t started migrating your analytics to the cloud, then hopefully this will convince you to start reconsidering. The opprtunity to have access to a 64, 96 or even 128 core machines with 2TB of RAM rarely crosses the path of most Data Scientists. This can mostly be accredited to the fact that most of us don’t really need such a large machine for what we need to achieve, see Szilard’s twitter posts if you need convincing. Another reason that we don’t use these big machines are purely because we just don’t have access to such machines within our working environments. Luckily for us, access to cloud computing have become more accessible and well, lets be honest, cheap as chips.
Using prebuilt AMIs
An AMI or Amazon Machine Image is a pre-built enviroment available to us as an all-inclusive environment containing the operating system and any other applications we might have installed, e.g Rstudio, MariaDB, Docker etc..
One of these AMIs, specifically built for analytics and deep learning in Rstudio, is maintained by Louis Aslett. This AMI is designed to fascilitate most applications using MCMC sampling such as Stan or Jags. It also takes away the headache of setting up an instance that is able to accommodate the Keras and Tensorflow interfaces on an Linux machine. In addition the image contains LaTeXand rmarkdown, along with various other installations to allow for a plug and play setup.
If you have ever try to do any of the above yourself, then you will know what achievement this is. So to Louis:

I have used Louis Aslett’s AMI and added rJava, as well as installed the caret and h2o libraries for us the play with. This AMI is publicly available. We can use the search functionality to look for the AMI under public images: ami-0157656a8c5b46458. For security reasons, I advise that you change the default port on which the Rstudio instance listens from port 80 to something random such as port 8765 if you gonna run this in production. If you want to do this, you will need to reconfigure the nginx server conf under /etc/nginx/sites-available.
To access the Rstudio setup once you get to the end of this post, navigate to the Public IP as indicated in the screenshot at the end and log in using the predefined credentials. For now the image uses4:
- user: rstudio
- pass: rstudioh2ocaret
To use one of these AMIs, we need to log into amazon and navigate to the EC2 dashboard. I use the Ohio region, so make sure that you set this region in the left had corner if you want the follow the setup of the AMI.
Well documented instructions on how to set up an AWS account are easily available on a multiple blogs, but I will show you how to find the AMI using the search function on the AWS website. Firstly, access your ec2 dashboard and go to the AMI tab on the left:
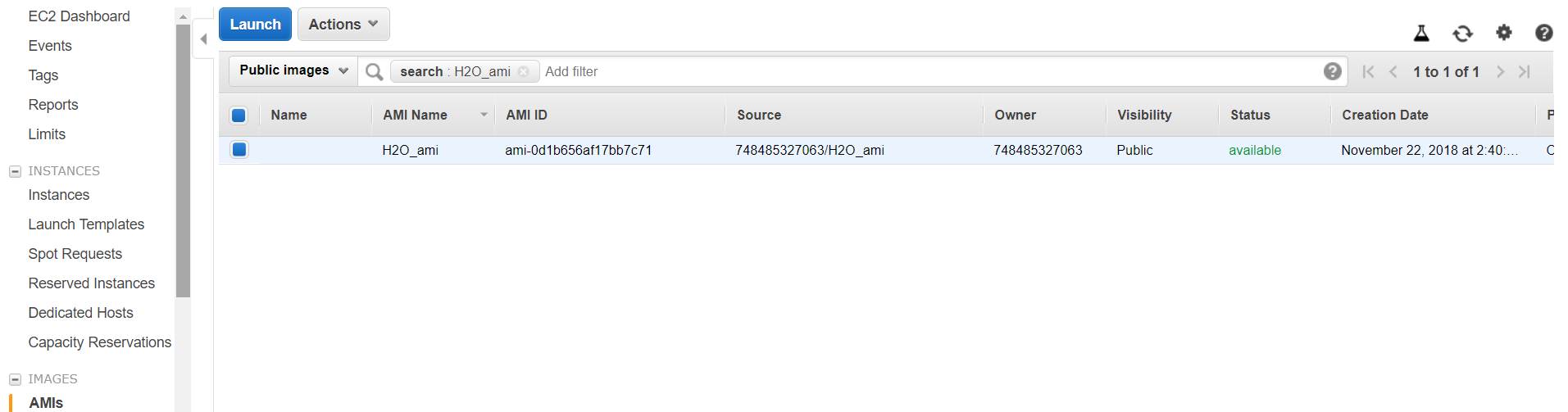
Setting up the AMI on a Spot instance
Whenever I use AWS, I prefer using Sport Instances:
A Spot Instance is an unused EC2 instance that is available for less than the On-Demand price. Because Spot Instances enable you to request unused EC2 instances at steep discounts, you can lower your Amazon EC2 costs significantly. The hourly price for a Spot Instance is called a Spot price
I typically use these machines anything from an hour to a couple of hours, so on-demand has never been a need. Never have the instances been a pain to get or have I been restricted to using an instance because usage suddenly spiked. These spot instances are the perfect way to keep costs low, while having access to HUGE machines.
Choose instance and configure:
Right click on the H2O_ami and select Spot Request. This will bring you to a screen showing the machine menu. For now, we won’t get too carried away, so lets select the r3.4xlarge image. This machine is one of my favourites, although its not part of the current generation machines, it is a memory optimised machine which works well for ML training:
- 16 cores
- 122GB RAM
- 1 x 320 SSD
- Spot Price: $0.1517/h
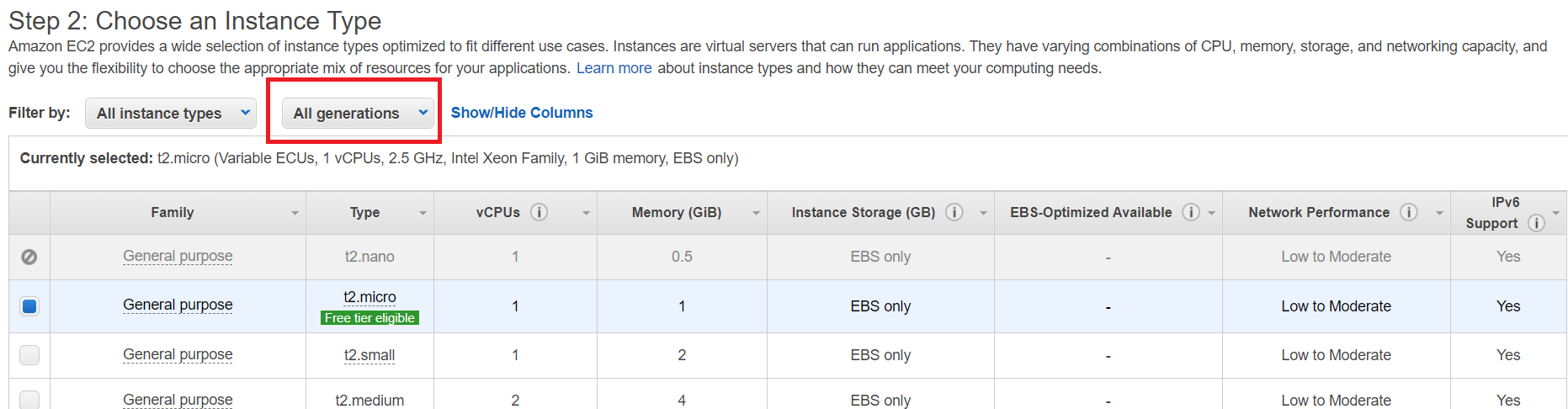
You can also configure the instance to shutdown when a maximum spot price is reached. In steps 4 and 5 you can add storage and tags if you want. I don’t show this, as we don’t want to get too bogged down in the detail, we want to get to the part where we play with H2O.
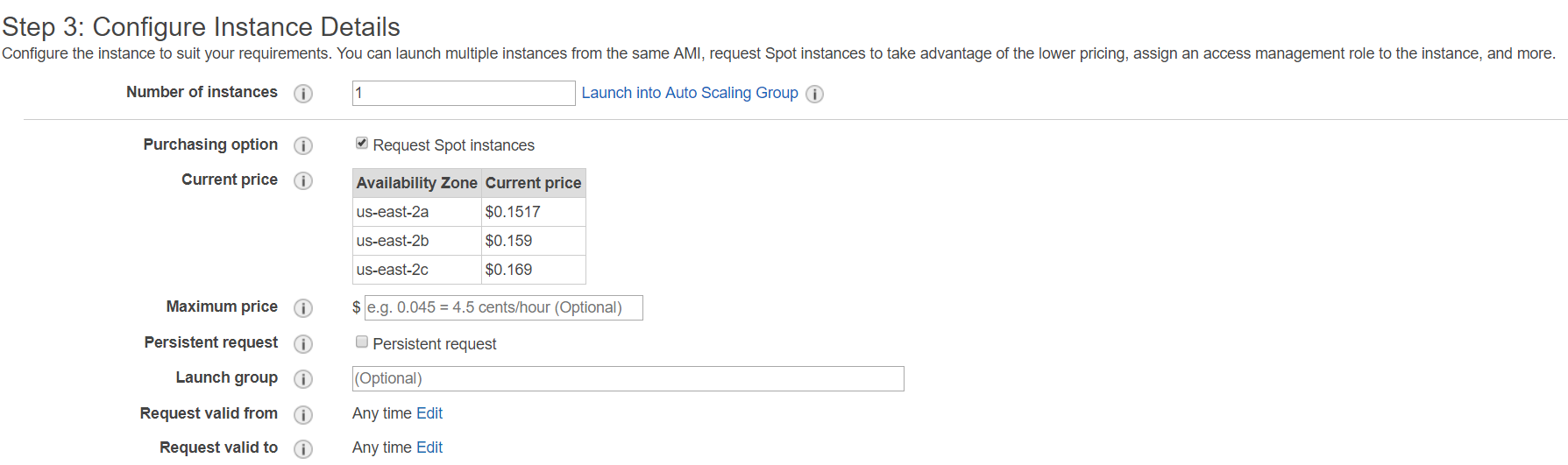
Add security group
In step 6, you have to configure the security group of the instance. For now, we are not going to setup any crazy configurations. We will open port 22 (ssh) and 80 (http) which will allow us to access the machine and Rstudio from anywhere. If safety is a concern, you can be a lot more specific on the configurations.
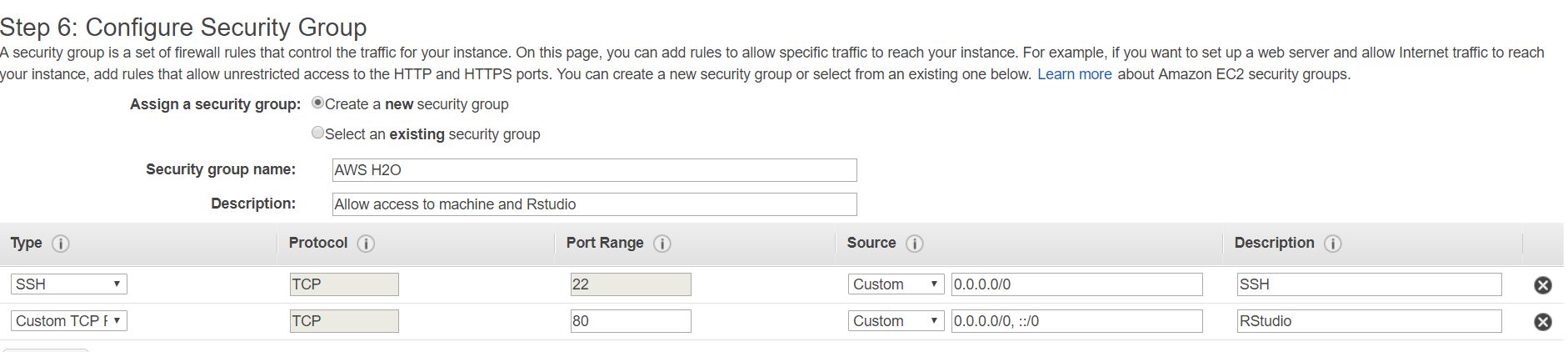
The final step before the instance is launched is confirming you have the appropriate key pair to access the machine:
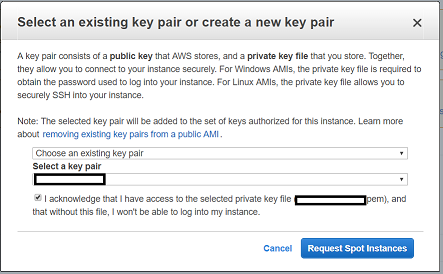
Once you have done this, you should be able to see your new instance being initialized in the Instance tab of your ec2 dashboard:
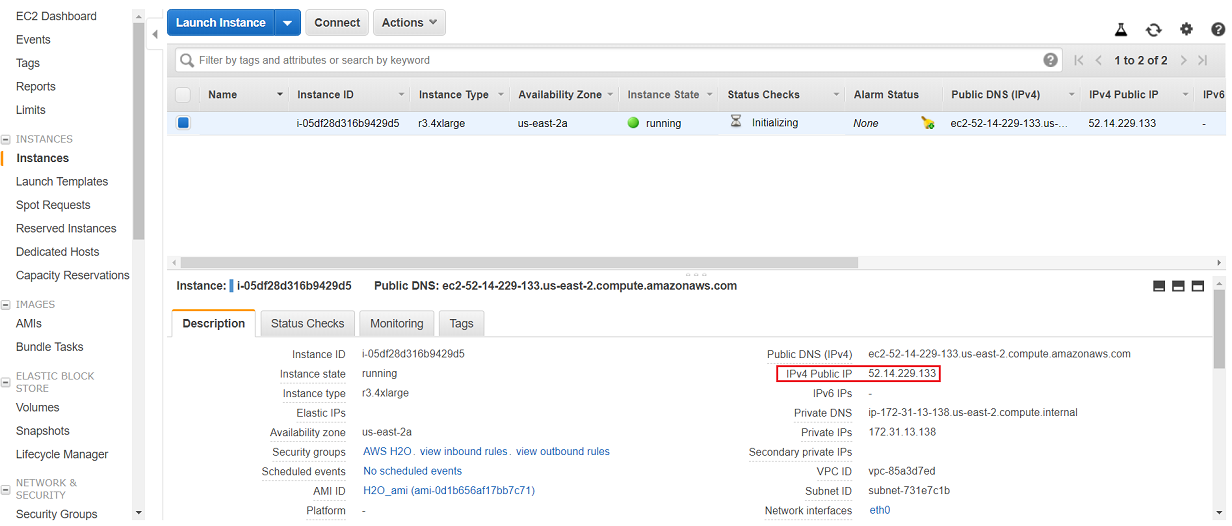
Well done, you have now spinned up a machine that is probably around 3 - 4 times bigger than your current working environment on a laptop or PC. Remember to terminate this machine when you are done with it!
To check that the machine has the 16 cores and 122GB RAM as promised, we can SSH5 into it and use the htop command to confirm:
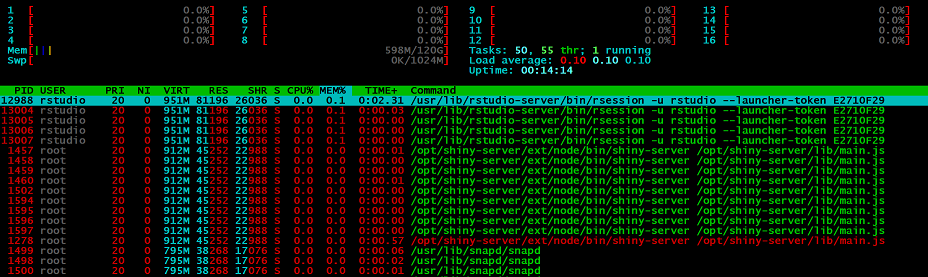
To access the Rstudio IDE, open a browser and go the the public IP provided. Once you have entered the username and password you should be given access to a welcome screen.
Well done! You now have access to an analytical system that is CPU/GPU enabled and can handle training of ML models using either caret or H2O.
I also recommend you read the Welcome.R file which contains information on the very helpful RStudioAMI package.
In the next post we gonna explore running models using the H2O api and combining it with purrr to create multiple model tibbles for easy evaluation
- Disclaimer:I don’t work for AWS, it is just the platform that I ended up using over the past year or so. I am sure Google Cloud (or any other cloud service) is just as good ^
- For those excited to see OLS in action, sorry to dissapoint, those aren’t ML models… ^
- I am looking at you
Error in nominalTrainWorkflow...^ - In future I would like to adjust this to the specifications that Louis had. In the original AMI, the password is the instance ID, which is very clever - unfortunately I haven’t been able to figure it out for this H2O AMI ^
- If you do not know about SSH you are probably working on a Windows machine - follow these instructions to install putty ^